

Dawn Pattison
October 26, 2023Data minimization: a privacy engineer’s guide on getting started
Our Senior Software Engineer Dawn Pattison walks you through implementing data minimization into your business.

What is data minimization?
Data minimization is a fundamental principle for building privacy-respecting software. In simplest terms, it’s the idea that we should collect the minimum amount of data needed to fulfill business purposes. This is a great step towards protecting your users’ privacy. Data cannot be misused if it is not in your possession.
For such a simple idea, data minimization can be tricky to implement, especially if you haven’t been adhering to this principle from the beginning. But, it’s never too late to start! This guide will go over how your business can start practicing data minimization.
How to practice data minimization
Here are the three steps your business needs to take to get started with data minimization:
- Define your business purposes
- Build your data map
- Apply data minimization tactics
We’ll go over each step in more detail down below, using a fictional business I own, called Dawn’s Coffee To-Go, as an example.
Step 1: Define your business purposes
Knowing why your business is collecting customers’ data is a prerequisite to data minimization. To get started, simply list out the reasons why your business collects customers’ personal data. Then, use a privacy taxonomy like Fideslang to categorize them.
Since privacy is such a complex challenge, with different regulations governing how categories of personal data should be treated, using a common privacy language like Fideslang helps improve interoperability and standardization across businesses.
Let’s see what this process looks like with Dawn’s Coffee To-Go (DCG).
DCG caters to busy working professionals, allowing them to order ahead of time and grab on their way to work. Here are some of the business reasons why I would need to collect customers’ data:
- Intake coffee orders via website
- Process payments
- Notify customers when their order is ready for pickup via email
- Deliver order to the correct person at the drive-through window
- Anticipate inventory needs
- Anticipate staffing needs
- Optionally collect anonymous feedback to improve service
- Increase customer loyalty by emailing Early Bird members to get their free birthday coffee, free coffee after every tenth item purchased, and information about new drinks.
I can now go through each business purpose and categorize it based on a Fideslang data use. Here’s what I would classify all of the above activities as:
- Essential for Service
- Essential Email Service Notifications
- Essential for Payment Processing
- Improve Service
- Marketing Email Communications
Now that we know why we need to collect customers’ data, let’s see how we can verify if we are actually collecting data only for these purposes.
Step 2: Build your data map
To see what data your business is currently collecting, create a data map or system inventory of all data processing activity.
Tools like the Fides privacy engineering and intelligence platform can help you manually add systems to your data map or use detection tools to automatically identify systems, and then attach data uses and processing activities. You can also use Fides to annotate which fields contain certain categories of personal data.
Let’s see how I would build a data map as DCG’s store owner.
DCG stores all internal data in a PostgreSQL database and uses Stripe for payment processing (which can be easily connected through the Fides Stripe Integration).
Below, you can see some of the fields in our sample data map including Data Use, Data Category, Data Subject, and Legal Basis for Processing. Note how DCG is using birthdays for Content Personalization – this will be important later on!
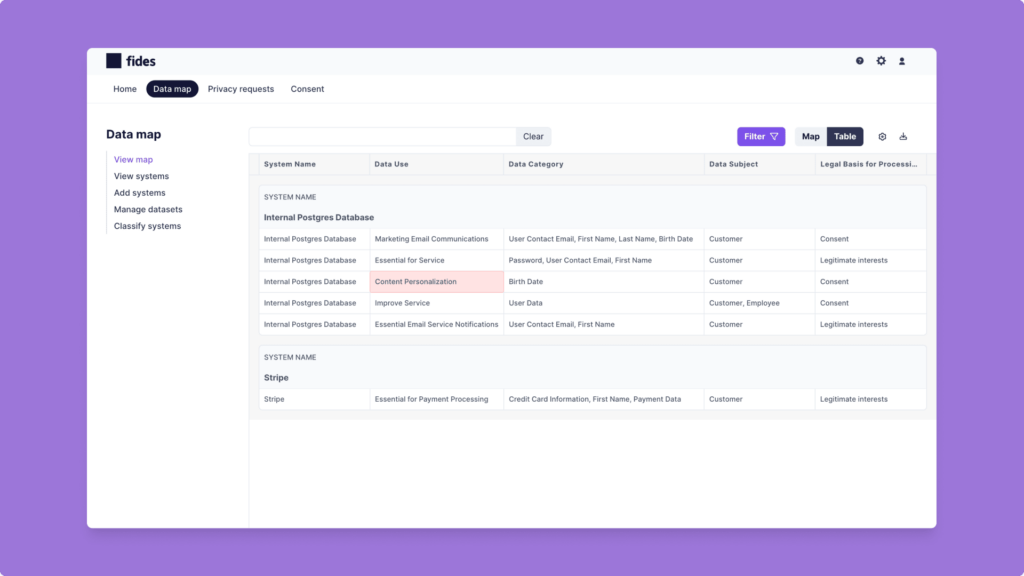
Looking further at our annotated Fides Datasets for our internal PostgreSQL database, we see there’s personally identifiable information (PII) in two tables: early_bird_accounts and coffee_orders.
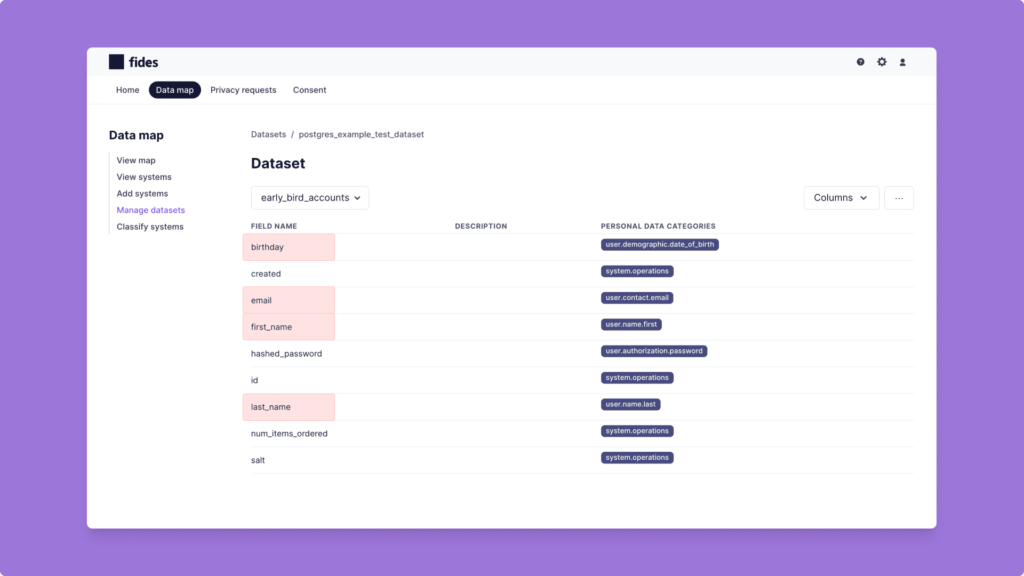

Step 3: Apply data minimization tactics
Now that we’ve pinpointed which fields contain PII, we should apply data minimization tactics to ensure each data field is used to support our business purposes.
A solid approach is to use the data minimization tactics from Jaap-Henk Hoepman’s Privacy Design Strategies (The Little Blue Book). These tactics are:
- Exclude
- Select
- Strip
- Destroy
Let’s focus on our internal early_bird_accounts and coffee_orders tables to illustrate how to apply these data minimization tactics.
Exclude
The first tactic of data minimization is deciding which attributes you should stop collecting across all users.
In DCG’s case, the birthday field in early_bird_accounts stands out as potentially problematic. Under the Marketing Email Communications purpose, we email Early Bird members on their birthday to redeem their free cup of coffee, which increases customer loyalty. However, we’ve been unnecessarily collecting their birth year to support this.
From our data map we’re actually repurposing customers’ birth years for Content Personalization – we change customers’ web experience based on their age. This is not a business purpose we identified in Step 1 above.
To remediate this, let’s disable Content Personalization immediately. Let’s also exclude collecting birth years across all customers going forward and do a one-time purge of birth years already collected. While we’re at it, we also don’t need to request their birthday specifically. Let’s rename the birthday column to annual_free_coffee_day. Then, update the signup form accordingly.
Select
The next data minimization tactic is deciding which attributes you need to collect for specific users.
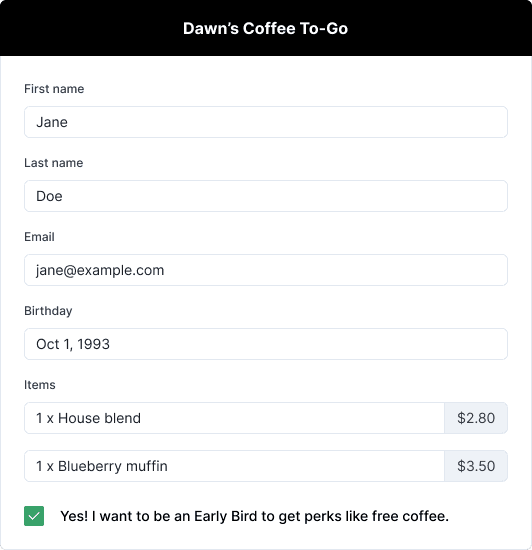
At DCG, customers don’t have to be Early Bird members; they should be able to order a cup of coffee without creating an account. However, as seen in the form above, we’ve been creating early_bird_accounts and collecting customers’ birthdays, regardless of whether they’ve signed up as an Early Bird. Our current order form is terribly misleading, and would create accounts and collect birthdays for non-Early Bird users for no reason.
Going forward, let’s rewire the checkbox to only create accounts if the checkbox is selected. Let’s also use that checkbox to trigger whether the birthday (now annual free coffee day) form input is revealed. The form below is much more aligned with our purposes.
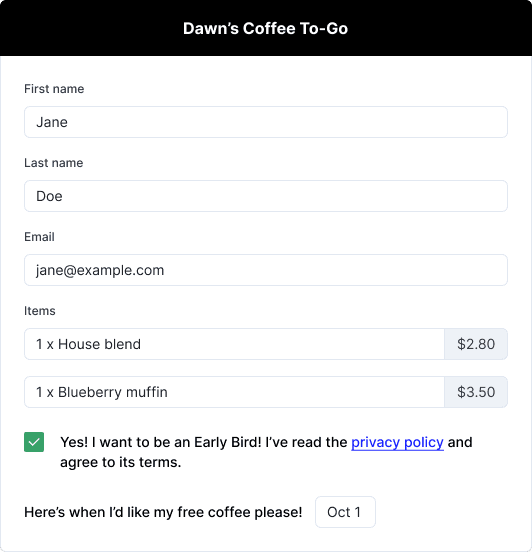
With the signup form fixed, we now need to address the data we’ve already collected under false pretenses. At this point, I can’t discern who actually wanted to be an Early Bird. The safest path might be to remove all accounts from the early_bird_accounts table and recollect Early Bird sign-ups with the new form going forward.
Actual Early Birds might be upset that I deleted their accumulated order count. But, to offset this, I could automatically credit every new account with the max num_items_ordered of 10. This would balance removing personal information that shouldn’t be on my servers with honoring commitments made to Early Birds for their customer loyalty.
Strip
Next, remove partial data as soon as it isn’t needed. In other words, we may not need all of the data that was entered into the field.
For example, DCG is collecting first and last names in the coffee_orders table to streamline delivering coffee to the right person at the drive-through. However, DCG probably doesn’t need their entire last name. Last initial will almost always be sufficient to distinguish between two orders. When a customer submits their order, I’ll just retain the first letter of their last name, and strip off the rest. For last names already collected, we can run a one-time query to strip off all but the first initial.
If there are still mixups, we can revert to using order items (House Blend and Muffin!) or fall back to email and order_number to uniquely identify the customer’s order.
Destroy
Lastly, completely remove personal data as soon as it is no longer relevant, or if it was accidentally collected.
Deleting data comes with its own set of risks. But, our data mapping exercise from Step 2 helps us determine how to delete data without breaking our website by surfacing which features rely on PII fields. Often, you will need to make some changes in your application code or database to remove dependencies on old data prior to its deletion. In our case, the Content Personalization was the only feature at risk, but we disabled this before deleting the birth year.
Unfortunately, DCG has been collecting coffee_orders for several years and has never deleted any information from that table. Some data is useful for anticipating future inventory and staffing needs, but we need much stricter retention periods on PII. It’s helpful to know customers order more standard House Blends at the beginning of the year with our specialty blends being more popular October-December, so they are stocked accordingly. But DCG certainly doesn’t need to know that Jane’s typical order of one House Blend and one Blueberry Muffin on Tuesday and Thursday mornings has suddenly doubled to two Muffins, one House Blend, and one Cappuccino.
The best way to keep up with retention periods is to set up an automated, recurring solution that deletes data on a schedule. Let’s add a nightly script that removes first_name and last_name (now last initial) from all coffee_orders placed that day, as the names are only used when the customer picks up their coffee order. Let’s keep the email for two months to retrieve the order where there are billing disputes, but then delete that identifier from the record too. Finally, for account holders, let’s automatically delete the entire record in the early_bird_accounts table once that account has been inactive for a year.
We already destroyed some accidentally-collected data with our previous data minimization tactics, but this is a good time to verify all that unnecessary data is gone, including removing this data from your backups.
Get started with data minimization!
Now that you’ve gone through all of the steps of data minimization with Dawn’s Coffee To-Go, you can start applying these steps to your own business. Simply follow all of the steps above and regularly review your business purposes and data map to make sure everything is up-to-date!
To learn more about how Ethyca can help your business easily practice data minimization, check out our data mapping solutions today.
Engineering Data Trust at Scale: A Conversation with Adrian Galvan, Senior Software Engineer
Read MoreAdrian Galvan builds scalable, privacy-first integrations at Ethyca.
From Paper to Power: Reflections on the 2025 Consero CPO Summit
Read MoreAt the Consero CPO Summit, it was clear: privacy leaders are shifting from compliance enforcers to strategic enablers of growth and AI readiness.
JustPark Chooses Ethyca to Power Global Privacy and Data Governance
Read MoreJustPark has selected Ethyca to power its privacy and data governance, enabling trusted, consent-driven data control as the company scales globally.
Closing the AI Accountability Gap: Solving Governance with Data Infrastructure
Read MoreWithout infrastructure to enforce it, AI governance becomes costly theater destined to fail at scale.
The Engineer’s Burden: Why Trustworthy AI Starts with the Data Layer
Read MoreTrustworthy AI begins with engineers ensuring clean, governed data at the source.
Google Tag Manager Is Now a Legal Risk: German Court Ruling Redefines the Consent Perimeter
Read MoreKey takeaways from a German court ruling that redefines consent requirements for using Google Tag Manager.
Ready to get started?
Our team of data privacy devotees would love to show you how Ethyca helps engineers deploy CCPA, GDPR, and LGPD privacy compliance deep into business systems. Let’s chat!
Speak with UsSign up to our Newsletter
Stay informed with the latest in privacy compliance. Get expert insights, updates on evolving regulations, and tips on automating data protection with Ethyca’s trusted solutions.

