

Cillian Kieran
October 22, 2021Devtools for Data Privacy — Step 2: Imagining the Benefits
Developer tools for data privacy, built to work in existing pipelines, offer immense potential for embedding privacy and respect into all tech stacks. Our CEO Cillian highlights the positive impacts of privacy devtools.
Why Solving This Problem Matters
If you’re in an agile dev team, particularly at a startup where shipping code matters most, it’s easy to think of privacy as a tax that slows down building things in order for legal teams to evaluate risks.
That doesn’t necessarily mean you don’t care about privacy. It means you have no efficient way to make it a part of your agile process. I believe it’s impossible to solve the world’s privacy problems without first making it easier for product-builders to do the right, respectful thing regarding user data. That’s why building devtools for privacy matters so much.
We can all see this around us already. Governments, driven by user fears of Big Tech, are increasingly regulating software development companies. Tech is the new oil, automotive, and financial services industries combined — all of which are highly regulated. In our regulated future, software and the engineers that build it will be required to ensure their systems comply with a myriad of complex regulations. These regulations often differ by geography, so if you’re building internet-scale tech that crosses continents, simply building a compliant product becomes a considerable challenge.
FTC Consent Decree
If you want to understand the consequence of this concretely, read the FTC’s 2019 Consent Decree against Facebook. The events that brought about the decree are multifaceted, but here is a brief synopsis: In contradiction of Facebook’s commitment to protecting users’ privacy, third-party developers were able to collect users’ personal information, even of users who had configured their settings to limit sharing to their Facebook friends. In the eyes of the FTC, Facebook failed to adequately assess and address third-party risk (recall that this transpired in the wake of the Cambridge Analytica scandal). Facebook had also asked users for phone numbers, with the stated purpose of security measures, to authenticate users who needed to reset their account passwords. Beyond the stated purpose, though, Facebook used phone numbers to deliver advertisements.
Aside from fining Facebook $5B — the largest fine ever imposed for a privacy violation, and some members of the FTC thought the penalties should have gone further — the decree laid out for Facebook a set of changes it must adopt to avoid further penalty.
The FTC outlined for Facebook the following, which trickles down to the entire dev community: If you write code that results in software that might collect, process or in some way munge users’ personal data, you must be able to describe what types of data you’re using, what you’re using them for and evidence of the risk mitigation strategies that were considered in doing so. This has to happen before you deploy!
A passage below from Section VII. E. 2(b), page 10 of the FTC Modifying Order Consent Decree:
IT IS FURTHER ORDERED that Respondent, in connection with any product, service, or sharing of Covered Information, shall establish and implement … safeguards that control for the material internal and external risks identified…
Such safeguards shall include…For each new or modified product, service, or practice that presents a material risk to the privacy, confidentiality, or Integrity of the Covered Information (e.g., a completely new product, service, or practice that has not been previously subject to a privacy review; a material change in the sharing of Covered Information with a Facebook-owned affiliate;)… producing a written report that describes…
The type(s) of Covered Information that will be collected, and how that Covered Information will be used, retained, and shared;…[and] existing safeguards that would control for the identified risks to the privacy, confidentiality, and Integrity of the Covered Information and whether any new safeguards would need to be implemented to control for such risks…
The implications of this directive are striking to consider. The FTC has directed the tech community to ensure that when code is written, we know what data it’s using, for what purpose, and how we’re going to limit those risks.
As I’ve written before, it’s analogous to the shift of security over the last ten years from being a post-deployment testing problem to being part of healthy development practises. Now, security is a normal and healthy part of any good dev’s attitude to coding.
What the FTC and regulators around the world are asking the people who write software to do is this: be accountable and thoughtful about the decisions you make in the code you write. Declare what data you’re using and why, and ensure that it’s not used for the wrong reasons at any time in the future.
That seemingly simple business requirement demands an entire set of tools that are missing in the average agile development process. In order to ensure your team can continue shipping as quickly — and thoughtfully — as possible, you’re going to need a process and tools to describe privacy and data processing characteristics of your systems according to agreed-upon definitions. With these tools, you can then review your systems, mitigate risks, and report on them if necessary.
What Does Privacy Look Like Today?
So what would those tools look like? A good starting point here is to consider what your tech stack looks like today, and how it might look in the future. As with any good software architect, plan for scale. Don’t just imagine what it will look like in your first deployment. Rather, ask yourself what will your tech stack look like when your company is successful and has a lot of users.
A good reference point for this is this article by A16Z’s Martin Casado, Matt Bornstein and Jennifer Li on Emerging Architectures for Modern Data Infrastructure.
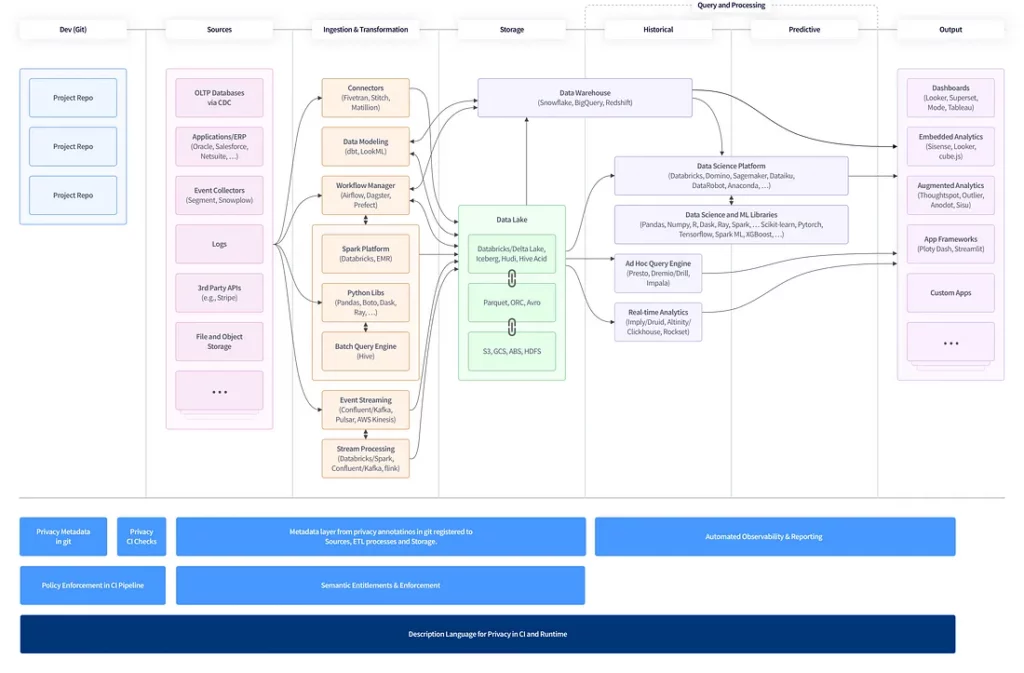
The diagram below shows what data infrastructure at scale ends up looking like — we’ve added what traditional privacy management looks like here, driven by the GRC (Governance, Risk, Compliance or Legal) teams.

As you can see, your venerable application has become a behemoth of data sources, ETL, storage and various layers of historical and predictive analytics.
In this, you’ll see that privacy and governance become roles shared by legal/governance and security but sit outside the architecture of the system with many tasks being managed manually — it is essentially a complex reporting structure rather than an active layer of the system.
There’s a simplified view of this that helps to parse each tranche of the data infrastructure which includes where privacy operations typically sit in the data lifecycle. You can see in the diagram below these happen after deployment, so code is already in production and much of the work revolves around post hoc data identification and risk mitigation.

While the largest companies with endless engineering resources are able to conduct manual privacy reviews during the building of each layer, the reality is much different in most cases. In a typical case, privacy happens after you’re deployed to production, after data collection has started and once there’s a realization of a potential risk.
And resolving it at this point becomes nearly impossible — data has been collected, its source or use is often unclear, and you’re already badly exposed to accidentally using it in a way that might break the law (Facebook’s painful example above).
The result is bolt-on tools that sit external to your core architecture. It’s quite literally slapping a bandaid over a deep structural issue in a complex system. That bandaid allows you to check a box, but your systems are still opaque. You still don’t understand where data is, so you have to do the work manually. Governance, compliance and metadata management become a manual burden for both legal and data engineering teams. For most developers, that burden shows up every so often as an unwanted, painful ticket that slows them down from the work they love most. The industry’s current approach to privacy is not only inefficient. It’s also detrimental to building a culture of privacy, pitting privacy against innovation. We can and must rework our collective approach to privacy, and that calls for new tools.
What Might Privacy Devtools Look Like?
Imagine an alternative to this painful remediative and refactoring work to mitigate risks after you’ve already deployed. Instead, you could add tools to your CI pipeline that would help to describe the data processing characteristics of your project and warn you if there are any risks as part of each commit or PR.
The result would be two powerful concepts:
- Data Context: because you’re tracking privacy metadata directly in git, you have context right from your source as to what types of data you’re using and for what purpose. Suddenly you have comprehensive oversight of data ingress and egress and its use. No more guessing.
- Data Control: because that metadata is now attached to every project that is deployed, your entire infrastructure is described. You know what type of data is flowing where and why. Controlling that data now becomes a breeze; after all, the hardest part is enforcement on a system with blind spots.
Since founding Ethyca three years ago, our incredible team of product, engineering and privacy specialists have been working to understand what this could look like.
The solution to this is developer tools built to integrate with existing developer workflows. We believe that the solution comprises the following set of tools, overlaid on the data infrastructure diagram below:

Description Language for Privacy
An ontology and open standard for how to describe privacy characteristics of your code and databases. Rather like Infrastructure as Code tools for DevOps, such as Terraform or Ansible, a Privacy as Code solution would allow any developer to easily describe and version privacy metadata directly in git, ensuring that your project declares the type of data it uses and the purposes for which it uses them.
If this is driven by an open, easily understood standard ontology and taxonomy, integrating systems and evaluating risk will become API driven and assured.
CI-Integrated Evaluation
Once you have the ability to declare privacy characteristics, it should be possible to describe policies that can be enforced directly on projects in CI, on commit or for each PR. This would mean that instead of complex human-in-the-loop privacy reviews with legal teams, your pipeline can check your projects against agreed company policies and nudge you if something doesn’t look right before you deploy. Like security tools, but to help quickly ensure your work meets the company requirements. This effort usually focuses on dataset metadata — so tagging data at rest. If the code you deploy already describes its context and types of data, this can now sidecar your runtime environment transactions, meaning you can see what data types flow where and for what purpose. Metadata becomes a living component of your software development process and updates synchronously with each change.
Semantic Enforcement
Because you have a consistent definition language for describing data behavior in your application; you can now use this same standard to enforce access or comply with regulations, be they today’s regulations or regulations a decade from now. The integrated nature of the tools and the standard definitions of data use in the language ensure that you have a foundation on which you can enforce new policies in future without having to refactor your complex production infrastructure.
Summary
This brings us full-circle to developer tools for privacy. We need to build tools that work in existing pipelines and allow us to quickly describe the behavior of our code and the data in our systems. From there, we can evaluate risks, report on them and make changes.
Achieving this requires an open standard for privacy behaviors and characteristics as well as risk evaluation tools that are wired directly into git and other CI tools to make privacy a streamlined, low-friction part of your dev process.
I’m confident and optimistic that this is possible. It’s what we’ve been working on for some time at Ethyca, and we’re excited to share results of that work with the dev community in the coming months. In the next year, you’ll see Ethyca publicly step forward to offer solutions and ideas that we’d like to share with the entire engineering community. Our aim is to make privacy a simple, natural and easily enforceable part of your development process. I can’t wait to share this with you. This problem matters for the sake of our industry and the health of privacy and data ethics everywhere.
Read More
This article is the second installment in a three-part series from CEO Cillian Kieran on privacy devtools and their underlying systems. Explore the rest of the trilogy:
Closing the AI Accountability Gap: Solving Governance with Data Infrastructure
Read MoreWithout infrastructure to enforce it, AI governance becomes costly theater destined to fail at scale.
The Engineer’s Burden: Why Trustworthy AI Starts with the Data Layer
Read MoreTrustworthy AI begins with engineers ensuring clean, governed data at the source.
Google Tag Manager Is Now a Legal Risk: German Court Ruling Redefines the Consent Perimeter
Read MoreKey takeaways from a German court ruling that redefines consent requirements for using Google Tag Manager.
The Knowledge-Action Gap in AI: What Real Governance Requires
Read MoreMost AI governance tools fail because they focus on observation over control -documenting risks without providing the infrastructure to act on them.
One Company, One Data Language: The Foundation of Trustworthy AI Innovation
Read MoreTrustworthy AI starts with speaking the same data language across the organization.
Navigating the New Federal AI Landscape: Implications for Businesses and the Role of Trust
Read MoreAligning enterprise strategy with the next era of federal AI oversight.
Ready to get started?
Our team of data privacy devotees would love to show you how Ethyca helps engineers deploy CCPA, GDPR, and LGPD privacy compliance deep into business systems. Let’s chat!
Speak with UsSign up to our Newsletter
Stay informed with the latest in privacy compliance. Get expert insights, updates on evolving regulations, and tips on automating data protection with Ethyca’s trusted solutions.

