Annotating data categories manually
In order to process privacy requests, Fides needs to know how to find and process the applicable categories of personal data. For example, if a data subject submits a request to have their personal data removed, Fides has to know where to find categories of personal data like user contact info, demographic info, or purchase history.
Fides uses metadata labels that describe each table and field in a database to indicate which fields contain personal data.
For example, if a table contains fields with user contact data, annotating it with the label user.contact from the FidesLang Taxonomy (opens in a new tab) instructs Fides to treat this information as contact information. The screenshot below shows a database table with Fides personal data categories assigned to each field:
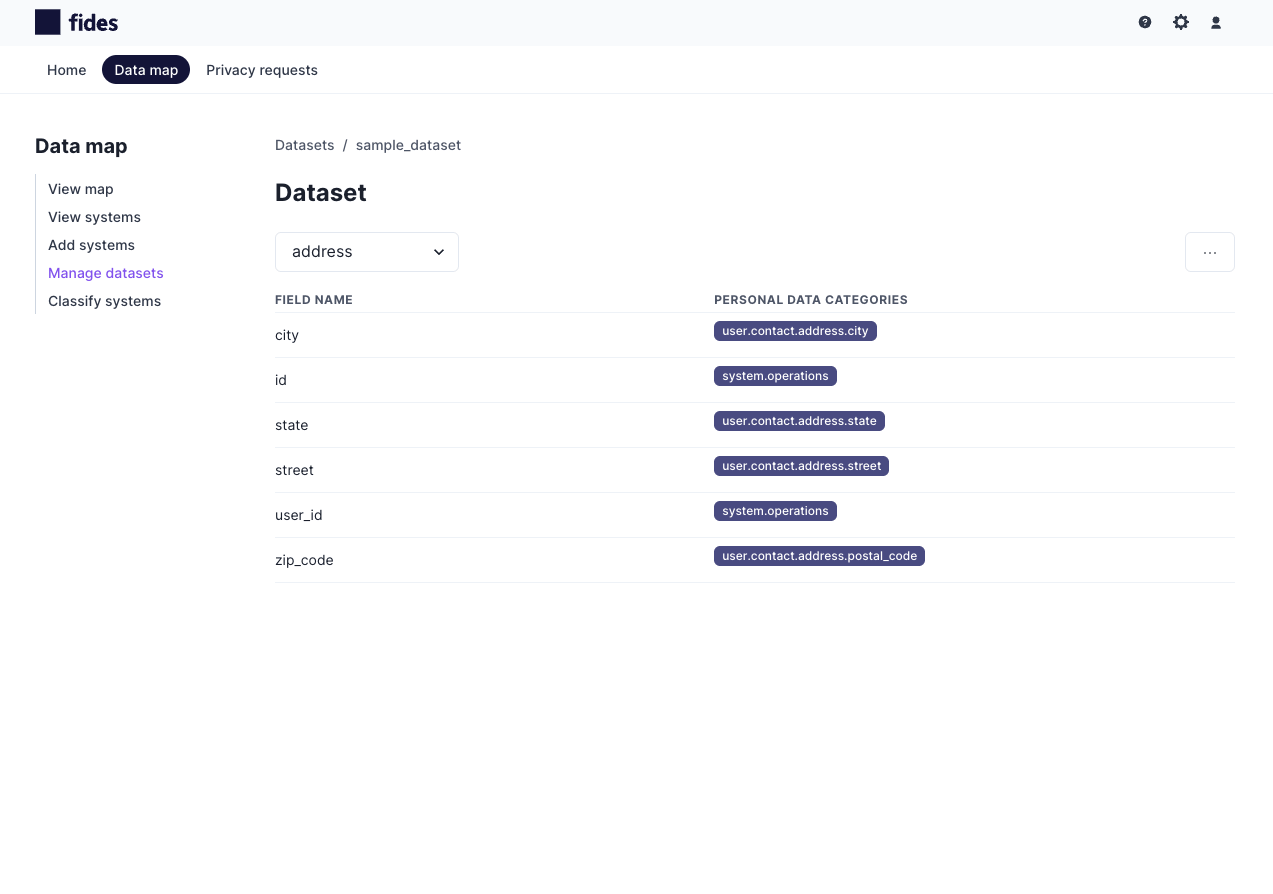
Annotating data categories
You can specify the data category for each field of a collection in a Fides dataset. Read about Fides dataset structures here. To learn about generating datasets read the guide here.
The dataset fields that will need to be configured are:
| Key | Value |
|---|---|
fides_key | The unique name of the dataset. |
collections | A list of tables or collection within the database. |
fields | The list of fields within the table or the collection. |
name | The name of the field within the table or collection. |
data_categories | The data category label taken from the FidesLang Taxonomy (opens in a new tab) to describe the personal data found in this field. |
The following example describes a table called customer within a database called postgres_example_dataset. This table has the fields id, email, name which have been appropriately labeled for privacy request processing.
collections:
- name: customer
fields:
- name: email
data_categories: # Add data categories section
- user.contact.email # Specify the data category (in this case email)
- name: id
data_categories:
- user.unique_id
fides_meta:
primary_key: True
- name: name
data_categories:
- user.name
fides_meta:
data_type: string
length: 40